Sparse, Quantize and Serving LLMs with NeuralMagic, AutoGPTQ and vLLM
A guide to explore Sparse techniques to compress LLMs

Summary
1. Brief review about Sparsity
2. Codes and Models
2.1 Recipes run a Sparse LLM
Execute a sparse LLM by NeuralMagic using vLLM
2.2 Recipes to Quantize a Sparse LLM with Marlin Kernel
Quantize a Sparse LLM with Marlin Kernel and AutoGPTQ
2.3 Recipes to Sparse a LLM
Sparse a LLM with SparseML
1. Brief review about Sparsity
The core idea behind sparse models is reduce memory-usage by ml models through weights pruning. When applying pruning the weights will come 0, which means a lot of time is spent waiting for the weights to be read.
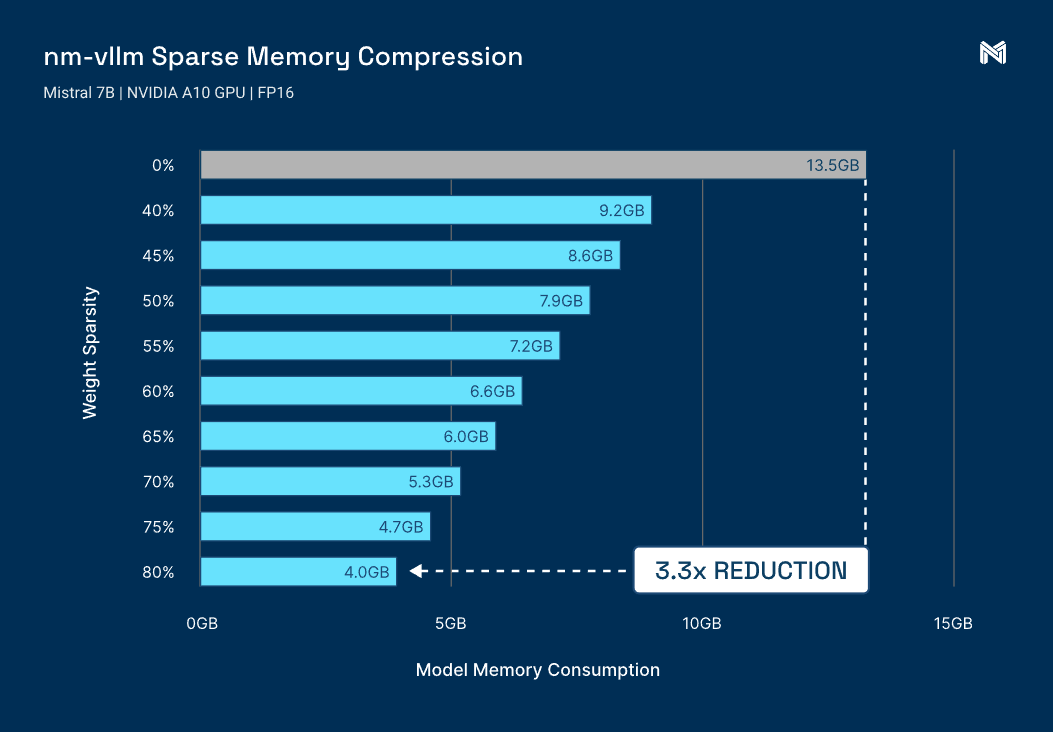

The Marlin Kernel accelerates inference over GPTQ using INT4 kernel. GPTQ is an algorithm to convert 16-bits weights to 4-bits. Quantizing reduces the model’s precision from FP16 to INT4 which effectively reduces the file size by ~70%. The main benefits are lower latency and memory usage.

nm-vllm supports many Hugging Face models out of the box, whether compressed or not. Some architectures of note are:
- GPT-2 (`gpt2`)
- GPT BigCode (`bigcode/starcoder`)
- GPT-J (`EleutherAI/gpt-j-6b`)
- GPT-NeoX (`EleutherAI/gpt-neox-20b`)
- LLaMA & LLaMA-2 (`meta-llama/Llama-2–70b-chat-hf`)
- Mistral (`mistralai/Mistral-7B-Instruct-v0.1`)
- Mixtral (`mistralai/Mixtral-8x7B-Instruct-v0.1`)
- MPT (`mosaicml/mpt-7b`)
- OPT (`facebook/opt-66b`)
- Phi (`microsoft/phi-2`)
- Qwen (`Qwen/Qwen-7B-Chat`)
- Qwen2 (`Qwen/Qwen-7B-Chat-beta`)
- StableLM (`stabilityai/stablelm-base-alpha-7b-v2`)
- Starcoder2 (`bigcode/starcoder2–3b`)
- Yi (`01-ai/Yi-34B`)
A collection of sparse models in HuggingFace Hub by NeuralMagic:
https://huggingface.co/collections/neuralmagic/compressed-llms-for-nm-vllm-65e73e3d51d3200e34b77431
2. Codes and Models
Attention, the codes requires a NVIDIA GPU with compute capability >= 8.0 (>=Ampere, A100 like) because of Marlin kernel and semistructured sparse restrictions. This will not run on T4 or V100. I used Google Colab Pro.
Codes are available on my Github.
2.1 Recipes run a Sparse LLM
First, install some deps
!pip install -U nm-vllm[sparse] transformersLoad with vLLM a pretrained Mistral-7B pruned 50%
from vllm import LLM, SamplingParams
# specify compressed kernel argument
llm = LLM(
model="neuralmagic/OpenHermes-2.5-Mistral-7B-pruned50",
sparsity="sparse_w16a16"
)Write some prompts
def format_prompt(prompt):
return f"<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant"
prompts = [
"The capital of the sun is",
"You are self conscious?",
"Akira Toriyama is",
"Yann LeCun is",
]
prompts = [format_prompt(prompt) for prompt in prompts]And run
# Define some model params
sampling_params = SamplingParams(max_tokens=100, temperature=0.8, top_p=0.95)
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"\nGenerated text: {prompt}{generated_text}\n")Clean session
# Cleanup
# restart session if not work
del llm
import gc
gc.collect()Inference via vLLM entrypoint (OpenAI compatible)
!python -m vllm.entrypoints.openai.api_server \
--model neuralmagic/OpenHermes-2.5-Mistral-7B-pruned50 --sparsity sparse_w16a16
2.2 Recipes to Quantize a Sparse LLM with Marlin Kernel
Here we will see as apply Marlin Kernel in a Sparse LLM using AutoGPTQ. At the end you can try my checkpoint.
!pip install auto-gptq==0.7.1 torch==2.2.1import argparse, gc, shutil
from transformers import AutoTokenizer
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
from datasets import load_dataset
model_id = "neuralmagic/OpenHermes-2.5-Mistral-7B-pruned50"
max_seq_len = 2048
num_samples = 512
def preprocess(example):
return {"text": tokenizer.apply_chat_template(example["messages"], tokenize=False)}
dataset = load_dataset("HuggingFaceH4/ultrachat_200k", split="train_sft[:5%]")
tokenizer = AutoTokenizer.from_pretrained(model_id)
ds = dataset.shuffle().select(range(num_samples))
ds = ds.map(preprocess)
examples = [
tokenizer(
example["text"], padding=False, max_length=max_seq_len, truncation=True,
) for example in ds
]
quantize_config = BaseQuantizeConfig(
bits=4, # Only support 4 bit
group_size=-1, # Set to g=128 or -1 (for channelwise)
desc_act=False, # Marlin does not suport act_order=True
model_file_base_name="model" # Name of the model.safetensors when we call save_pretrained
)
model = AutoGPTQForCausalLM.from_pretrained(
model_id,
quantize_config,
device_map="auto"
)
model.quantize(examples)
gptq_save_dir = "./tmp-gptq"
print(f"Saving gptq model to {gptq_save_dir}")
model.save_pretrained(gptq_save_dir)
tokenizer.save_pretrained(gptq_save_dir)
del model
gc.collect()
Save Model
# apply marlin kernels
save_sparse_marlin_dir = "openhermes-pruned50-marlin"
marlin_model = AutoGPTQForCausalLM.from_quantized(
gptq_save_dir,
use_marlin=True,
device_map="auto")
marlin_model.save_pretrained(save_sparse_marlin_dir)
tokenizer.save_pretrained(save_sparse_marlin_dir)Upload to HuggingFace Hub (optional)
from huggingface_hub import notebook_login
notebook_login()# Upload the output model to Hugging Face Hub
import os
from huggingface_hub import HfApi
hf_username = "YOUR_HF_USER"
final_model_name = os.path.join(hf_username, "OpenHermes-2.5-Mistral-7B-Pruned50-GPTQ-Marlin")
HfApi().create_repo(final_model_name)
HfApi().upload_folder(
folder_path=save_sparse_marlin_dir,
repo_id=final_model_name,
)!python -m vllm.entrypoints.openai.api_server \
--model vilsonrodrigues/OpenHermes-2.5-Mistral-7B-Pruned50-GPTQ-Marlin --sparsity sparse_w16a162.3 Recipes to Sparse a LLM
In the end we will spasify a LLM
!pip install sparseml-nightly==1.7.0.20240304 sparseml[transformers]import sparseml.transformers
original_model_name = "NousResearch/Hermes-2-Pro-Mistral-7B"
calibration_dataset = "open_platypus"
output_directory = "output_sparse_model/"
recipe = """
test_stage:
obcq_modifiers:
SparseGPTModifier:
sparsity: 0.5
sequential_update: true
targets: ['re:model.layers.\d*$']
"""
# Apply SparseGPT to the model
sparseml.transformers.oneshot(
model=original_model_name,
dataset=calibration_dataset,
recipe=recipe,
output_dir=output_directory,
)
Upload model to HF Hub (optional)
# Upload the output model to Hugging Face Hub
import os
from huggingface_hub import HfApi
hf_username = "YOUR_HF_USER"
final_model_name = os.path.join(hf_username, "Hermes-2-Pro-Mistral-7B-Pruned50")
HfApi().create_repo(final_model_name)
HfApi().upload_folder(
folder_path=output_directory,
repo_id=final_model_name,
)!python -m vllm.entrypoints.openai.api_server \
--model vilsonrodrigues/Hermes-2-Pro-Mistral-7B-Pruned50 --sparsity sparse_w16a16Considerations
I noticed a performance drop when applying sparsify
References
heavily based-on
