Serving Falcon models with 🤗 Text Generation Inference (TGI)
Run your LLM eficiently with TGI and LangChain integration

In previous post, we see as run your private Falcon-7b-Instruct in a single GPU of 6GB using quantization. Today, I’ll show how to run Falcon models on-premise and in the cloud. Notebook to reproduce here.
🤗 Text Generation Inference is a model serving production-ready designed by HuggingFace to power LLMs apps easily. It is powered by Python, Rust and gRPC. Under by Apache 2.0 license.
TGI Features
Some features listed in TGI repo are:
- Serve the most popular Large Language Models with a simple launcher
- Tensor Parallelism for faster inference on multiple GPUs
- Token streaming using Server-Sent Events (SSE)
- Continuous batching of incoming requests for increased total throughput
- Optimized transformers code for inference using flash-attention and Paged Attention on the most popular architectures
- Quantization with bitsandbytes and GPT-Q
- Safetensors weight loading
- Watermarking with A Watermark for Large Language Models
- Logits warper (temperature scaling, top-p, top-k, repetition penalty, more details see transformers.LogitsProcessor)
- Stop sequences
- Log probabilities
- Production ready (distributed tracing with Open Telemetry, Prometheus metrics)
Optimized architectures
Other architectures are supported on a best effort basis using:
AutoModelForCausalLM.from_pretrained(<model>, device_map="auto")
or
AutoModelForSeq2SeqLM.from_pretrained(<model>, device_map="auto")
TGI Routers
The best way to explore TGI routers is the swagger page:
- /info — [GET] — Text Generation Inference endpoint info
- /metrics — [GET] — Prometheus metrics scrape endpoint
- /generate — [POST] — Generate tokens
- /generate_stream — [POST] — Generate a stream of token using Server-Sent Events
- / — [POST] — Generate tokens if
stream == falseor a stream of token ifstream == true
Serving
🤗 provide a Docker image (9.32GB):
ghcr.io/huggingface/text-generation-inferenceTGI Parameters
TGI configs
- model-id <MODEL_ID>
- revision <REVISION>
- sharded <SHARDED>
- num-shard <NUM_SHARD>
- quantize <QUANTIZE>
- trust-remote-code
- max-concurrent-requests <MAX_CONCURRENT_REQUESTS>
- max-best-of <MAX_BEST_OF>
- max-stop-sequences <MAX_STOP_SEQUENCES>
- max-input-length <MAX_INPUT_LENGTH>
- max-total-tokens <MAX_TOTAL_TOKENS>
- max-batch-size <MAX_BATCH_SIZE>
- waiting-served-ratio <WAITING_SERVED_RATIO>
- max-batch-total-tokens <MAX_BATCH_TOTAL_TOKENS>
- max-waiting-tokens <MAX_WAITING_TOKENS>
- port <PORT>
- shard-uds-path <SHARD_UDS_PATH>
- master-addr <MASTER_ADDR>
- master-port <MASTER_PORT>
- huggingface-hub-cache <HUGGINGFACE_HUB_CACHE>
- weights-cache-override <WEIGHTS_CACHE_OVERRIDE>
- disable-custom-kernels
- json-output
- otlp-endpoint <OTLP_ENDPOINT>
- cors-allow-origin <CORS_ALLOW_ORIGIN>
- watermark-gamma <WATERMARK_GAMMA>
- watermark-delta <WATERMARK_DELTA>
- envWow, many options 😬, but it’s good, excellent work by 🤗 devs 👨💻. Some params we will to use as env:
# share a volume with the Docker container to avoid
# downloading weights every run
volume=$PWD/data # model on 🤗 Hub
model=tiiuae/falcon-7b-instruct
# apply quant to reduce gpu consume
quantize=bitsandbytesFalcon-7b models do not support Shard (Tensor Parallelism).
num_shard=1Observations (update in 06/15/23)
- Can be necessary add
--trust-remote-codein Docker Args, although it was theoretically solved in https://github.com/huggingface/text-generation-inference/pull/396
2. For Falcon-40B models that allows shard, you should add:
--sharded true --num-shard NUM_GPUS3. bitsandbytes default quantization was designed for training, not inference, it is expected to be slower than normal. Quantization in GPT-Q and SQPR is already being added, should improve the inference.
4. Volta GPUs (e.g. V100) not support Falcon Models
Updates (07/01/23)
TGI v0.9.0 support now:
- PagedAttention (vLLM)
- GPT-Q (quantization)
Updates (07/13/23)
Falcon models now it has official support by HuggingFace. trust-remote-codeit is no longer necessary.
Updates (07/18/23)
TGI supports LLaMA 2 models and integrate Flash Attention V2.
Run in On-premise environment
You will need to configure NVIDIA Container Toolkit to use GPUs.
docker run --gpus all --shm-size 1g -p 8080:80 \
-v $volume:/data \
ghcr.io/huggingface/text-generation-inference:latest \
--model-id $model --num-shard $num_shard \
--quantize $quantizeBash tests
curl 127.0.0.1:8080/generate \
-X POST \
-d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":17}}' \
-H 'Content-Type: application/json'curl 127.0.0.1:8080/generate_stream \
-X POST \
-d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":17}}' \
-H 'Content-Type: application/json'curl 127.0.0.1:8080/ \
-X POST \
-d '{"inputs":"What is Deep Learning?",
"parameters":{"max_new_tokens":17},
"stream": True}' \
-H 'Content-Type: application/json'TGI Client
!pip install text-generationfrom text_generation import Client
# Generate
client = Client("http://127.0.0.1:8080")
print(client.generate("What is Deep Learning?", max_new_tokens=17).generated_text)
# Generate stream
text = ""
for response in client.generate_stream("What is Deep Learning?", max_new_tokens=17):
if not response.token.special:
text += response.token.text
print(text)LangChain
# Some error in colab. fix with
import locale
locale.getpreferredencoding = lambda: "UTF-8"!pip install langchain transformers# Wrapper to TGI client with langchain
from langchain.llms import HuggingFaceTextGenInference
inference_server_url_local = "http://127.0.0.1:8080"
llm_local = HuggingFaceTextGenInference(
inference_server_url=inference_server_url_local,
max_new_tokens=400,
top_k=10,
top_p=0.95,
typical_p=0.95,
temperature=0.7,
repetition_penalty=1.03,
)from langchain import PromptTemplate, LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate(
template=template,
input_variables= ["question"]
)
llm_chain_local = LLMChain(prompt=prompt, llm=llm_local)llm_chain_local("your question")RunPod
RunPod is a cloud computing platform, primarily designed for AI and machine learning applications. Our key offerings include GPU Instances, Serverless GPUs, and AI Endpoints. — (https://docs.runpod.io/docs/about)
🤑Pricing
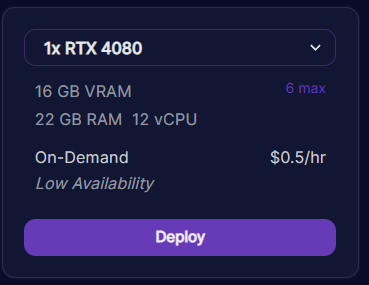
Based-on previous tests in Colab. 1 RTX 4080 it’s enough to run falcon-7b-instruct quantized.
!pip install runpodimport runpod
# your key
runpod.api_key = '...'num_shard = 1
model_id = "tiiuae/falcon-7b-instruct"
quantize = "bitsandbytes"
pod = runpod.create_pod(
name="Falcon-7B-Instruct-POD",
image_name="ghcr.io/huggingface/text-generation-inference:latest",
gpu_type_id="NVIDIA GeForce RTX 4080",
cloud_type="COMMUNITY",
docker_args=f"--model-id {model_id} --num-shard {num_shard} --quantize {quantize}",
gpu_count=num_shard,
volume_in_gb=50,
container_disk_in_gb=5,
ports="80/http",
volume_mount_path="/data",
)from langchain.llms import HuggingFaceTextGenInference
inference_server_url_cloud = f"https://{pod["id"]}-80.proxy.runpod.net"
llm_cloud = HuggingFaceTextGenInference(
inference_server_url=inference_server_url_cloud,
max_new_tokens=1000,
top_k=10,
top_p=0.95,
typical_p=0.95,
temperature=0.3,
repetition_penalty=1.03,
)llm_chain_cloud = LLMChain(prompt=prompt, llm=llm_cloud)Test
llm_chain_cloud("your new question to falcon")# stop pod
runpod.stop_pod(pod["id"])
# terminate
runpod.terminate_pod(pod["id"])AWS Support to TGI
Considerations
TGI is a fantastic tool to run Large Language Models efficiently and production-ready. I hope that I could have helped you!
🤠 Thanks for reading. See you later in the next posts.
References
Thanks Pavel to show how to use on RunPod
