Run your private LLM: Falcon-7B-Instruct with less than 6GB of GPU using 4-bit quantization
Building with BitsAndBytes, HuggingFace and LangChain

Falcon is a fully open-source model launch by TII under Apache 2.0 license.
Falcon LLM is a foundational large language model (LLM) with 40 billion parameters trained on one trillion tokens. TII has now released Falcon LLM — a 40B model.
The model uses only 75 percent of GPT-3’s training compute, 40 percent of Chinchilla’s, and 80 percent of PaLM-62B’s.

On OpenLLM Leaderboard in HuggingFace, Falcon is the top 1, suppressing META’s LLaMA-65B.
Falcon is a 40 billion parameters autoregressive decoder-only model trained on 1 trillion tokens. It was trained on 384 GPUs on AWS over the course of two months.
Pretraining data was collected from public crawls of the web to build the pretraining dataset of Falcon. Using dumps from CommonCrawl, after significant filtering (to remove machine generated text and adult content) and deduplication, a pretraining dataset of nearly five trillion tokens was assembled.
Falcon has a younger brother of 7B of parameters, trained on 1.5T tokens. Both was fine-tuned in instruct datasets. The downside is that the model has a sequence length 2048 tokens.
Falcon-7B-Instruct has ~15GB of disk size, how to put on a gpu with less than 6GB? Quantization.
Prepare the model
bitsandbytes is a amazing library to apply quantization in Deep Learning models. HuggingFace launched integration with bnb. In this post they explain how run models using 4-bit quantization.
I performed these steps in Colab. But before I need convert the original weights in chuncks smallers to load efficiently using Accelerate. As the original weights are large, it consumed all RAM in the environment.
Use my notebook to reproduce.
Dependencies
!pip install -q -U bitsandbytes
!pip install -q -U git+https://github.com/huggingface/transformers.git
!pip install -q -U git+https://github.com/huggingface/peft.git
!pip install -q -U git+https://github.com/huggingface/accelerate.git
!pip install -q -U einops
!pip install -q -U safetensors
!pip install -q -U torch
!pip install -q -U xformersbitsandbytes configs
The 4bit integration comes with 2 different quantization types: FP4 and NF4. The NF4 dtype stands for Normal Float 4 and is introduced in the QLoRA paper
You can switch between these two dtype using bnb_4bit_quant_type from BitsAndBytesConfig. By default, the FP4 quantization is used.
This saves more memory at no additional performance — from our empirical observations, this enables fine-tuning llama-13b model on an NVIDIA-T4 16GB with a sequence length of 1024, batch size of 1 and gradient accumulation steps of 4.
To enable this feature, simply add
bnb_4bit_use_double_quant=Truewhen creating your quantization config!— by HuggingFace
We will used NF4!
Emphasizing that the computation follows on float16.
import torch
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)Load model
# My version with smaller chunks on safetensors for low RAM environments
model_id = "vilsonrodrigues/falcon-7b-instruct-sharded"
from transformers import AutoModelForCausalLM, AutoTokenizer, pipelinemodel_4bit = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
quantization_config=quantization_config,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
Wow. Our Linear Layers was quantized in 4-bits.
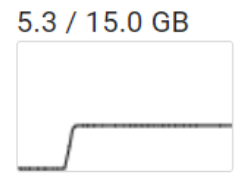
Checking VRAM consumption in Colab and …. 5.3GB of VRAM? 🤯
Define the pipeline
pipeline = pipeline(
"text-generation",
model=model_4bit,
tokenizer=tokenizer,
use_cache=True,
device_map="auto",
max_length=296,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.eos_token_id,
)Test
pipeline("""Girafatron is obsessed with giraffes, the most glorious animal
on the face of this Earth. Giraftron believes all other animals
are irrelevant when compared to the glorious majesty of the
giraffe.\nDaniel: Hello, Girafatron!\nGirafatron:""")"Hello, Danny!\nDanny: You know, I've noticed that your
obsession with giraffes has not changed since we last
met!\nGirafatron: I love the long-legged ones!\nDanny:
And here's something else I've noticed...your
girafanomania may have been triggered from the fact
that you never had one. Have you got a pet giraffe?
\nGirafatron: No, unfortunately. I don't have enough
space for one, and I'm not rich enough to buy one.
\nDanny: It's a shame about that...but I have a
feeling you could take care of a"Integrate with LangChain
LangChain is a versatile framework designed to empower the development of language model-powered applications. By harnessing the capabilities of LangChain, we can rapidly create powerful and efficient applications⚡.
# Some error in colab. fix with
import locale
locale.getpreferredencoding = lambda: "UTF-8"!pip install langchainLet’s create a simple Chain
from langchain import HuggingFacePipeline
from langchain import PromptTemplate, LLMChain
llm = HuggingFacePipeline(pipeline=pipeline)
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate(
template=template,
input_variables= ["question"]
)
llm_chain = LLMChain(prompt=prompt, llm=llm)
llm_chain("Write your question")Falcon models are a win for the open-source community. But yet are not ChatGPT. It is also not one of the fastest token generation models. Expectations need to be tempered. Even so, it is possible to do basic applications with the 7B. For something more robust you should go for the 40B.
Thanks 🤠
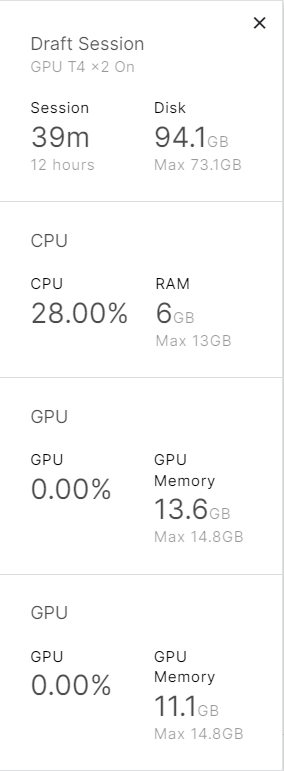
Bonus (07/01/2023)
Using model_id = ‘h2oai/h2ogpt-oasst1-falcon-40b’ (get weights only, not adapter) in a kaggle instance with 2 x T4
🧐See too
