Run LLAMA 2 models in a Colab instance using GGML and CTransformers
Try new META AI models in free enviroments

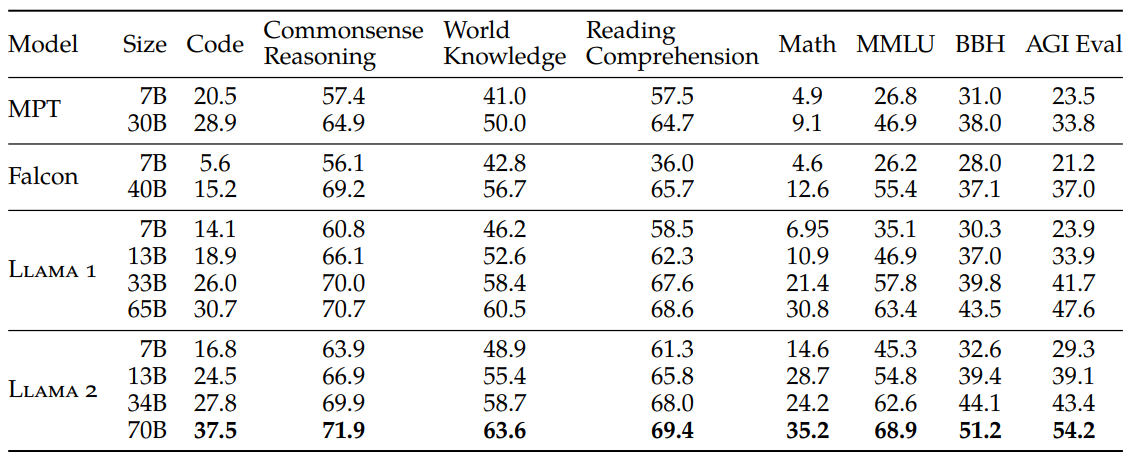
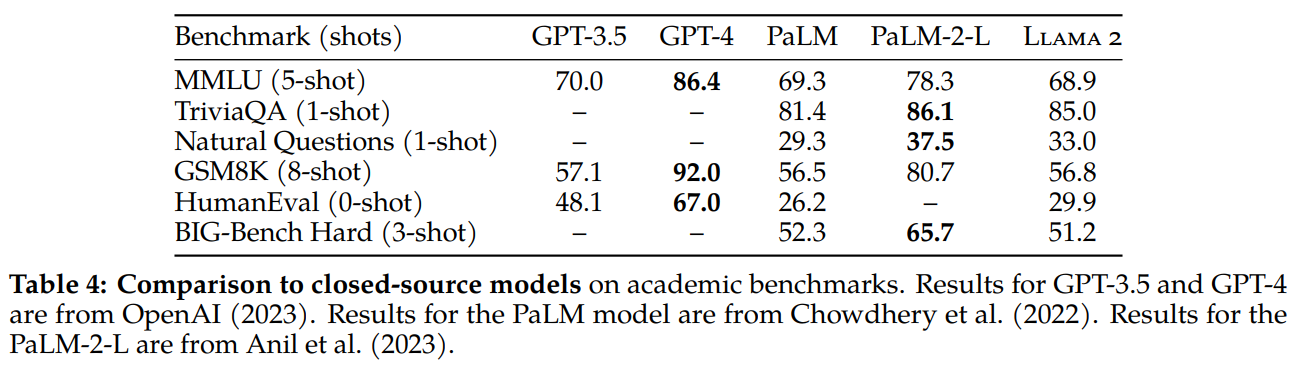
LLAMA-V2. META released a set of models, foundation and chat-based using RLHF. 7B, 13B, 34B (not released yet) and 70B. Free for commercial use!
Paper:
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
Review:
https://www.interconnects.ai/p/llama-2-from-meta
GGML is a tensor library, no extra dependencies (Torch, Transformers, Accelerate), CUDA/C++ is all you need for GPU execution. CTransformers is a python bind for GGML. Let’s use the weights converted by TheBloke.
Notebook to reproduce here.
Dependencies
# for GPU use
!CT_CUBLAS=1 pip install ctransformers --no-binary ctransformersChoose your model
# choose your champion
#model_id = "TheBloke/Llama-2-7B-GGML"
#model_id = "TheBloke/Llama-2-7B-chat-GGML"
#model_id = "TheBloke/Llama-2-13B-GGML"
model_id = "TheBloke/Llama-2-13B-chat-GGML"Configure model and load with CTransformers
from ctransformers import AutoModelForCausalLM
# check ctransformers doc for more configs
config = {'max_new_tokens': 256, 'repetition_penalty': 1.1,
'temperature': 0.1, 'stream': True}
llm = AutoModelForCausalLM.from_pretrained(
model_id,
model_type="llama",
#lib='avx2', for cpu use
gpu_layers=130, #110 for 7b, 130 for 13b
**config
)Inference Tests
I’ll to use two prompts in my tests
prompt="""Write a poem to help me remember the first 10 elements on the periodic table, giving each
element its own line."""
# pt-br for multilingual eval
prompt2="""Quando e por quem o Brasil foi descoberto?"""Tokenize for generate tests
tokens = llm.tokenize(prompt)LLAMA-V2-7B-Chat
Pipeline Execution
llm(prompt, stream=False)Generation
I. Hydrogen (H)
II. Helium (He)
III. Lithium (Li)
IV. Beryllium (Be)
V. Boron (B)
VI. Carbon (C)
VII. Nitrogen (N)
VIII. Oxygen (O)
IX. Fluorine (F)
X. Neon (Ne)
Each element has its own unique properties and characteristics,
From the number of protons in their nucleus to how they bond with other elements.
Hydrogen is lightest, helium is second, lithium is third,
Beryllium is toxic, boron is a vital nutrient,
Carbon is the basis of life, nitrogen is in the air we breathe,
Oxygen is what makes water wet, fluorine is a poisonous gas,
Neon glows with an otherworldly light.llm(prompt2, stream=False)O Brasil foi descoberto em 1500, quando os exploradores europeus chegaram ao
litoral do país. A descoberta do Brasil é creditada a Fernão de Noronha, que
foi o primeiro a navegar pelo litoral da região. No entanto, é importante
destacar que a presença indígena no território brasileiro remonta a 800 anos
antes da chegada dos colonizadores europeus.Stream Execution
import time
start = time.time()
NUM_TOKENS=0
print('-'*4+'Start Generation'+'-'*4)
for token in llm.generate(tokens):
print(llm.detokenize(token), end='', flush=True)
NUM_TOKENS+=1
time_generate = time.time() - start
print('\n')
print('-'*4+'End Generation'+'-'*4)
print(f'Num of generated tokens: {NUM_TOKENS}')
print(f'Time for complete generation: {time_generate}s')
print(f'Tokens per secound: {NUM_TOKENS/time_generate}')
print(f'Time per token: {(time_generate/NUM_TOKENS)*1000}ms')Generation + stats
----Start Generation----
I. Hydrogen (H)
II. Helium (He)
III. Lithium (Li)
IV. Beryllium (Be)
V. Boron (B)
VI. Carbon (C)
VII. Nitrogen (N)
VIII. Oxygen (O)
IX. Fluorine (F)
X. Neon (Ne)
I hope this helps me remember the first 10 elements on the periodic table!
----End Generation----
Num of generated tokens: 110
Time for complete generation: 7.801689863204956s
Tokens per secound: 14.099509456123355
Time per token: 70.92445330186324msLLAMA-V2–13B-Chat
Pipeline Execution
llm(prompt, stream=False)Generation
I'm trying to learn these in order to pass my chemistry class, and I find it
hard to remember them all. Any help would be appreciated!
Thank you!"
Of course, I'd be happy to help! Here is a poem to help you remember the first 10 elements on the periodic table:
Hydrogen is number one, a lightest element of all,
Boring and unreactive, it's hard to recall.
Helium's next, with a voice so high and thin,
In balloons it's used, and makes them fly within.
Lithium follows, with a charge so strong,
It's in your phone and other devices all day long.
Beryllium's next, a element so rare,
In gemstones it's found, and adds beauty there.
Boron's the next, with a name so fun,
In insecticides it's used, to keep them done.
Carbon's the king, of all elements we know,
From diamonds to coal, it's found in many a show.
Nitrogen'sllm(prompt2, stream=False)
A descoberta do Brasil é um evento histórico que ocorreu em 1500, quando a
expedição de Pedro Álvares Cabral alcançou as costas do atual Brasil. A
expedição partiu da Portugal em 2 de abril de 1500 e chegou ao Brasil em
22 de maio do mesmo ano.
A descoberta do Brasil é creditada a Pedro Álvares Cabral, que foi o líder
da expedição. Ele era um navegador português que havia participado de outras
viagens para o leste da África e para a Índia. A expedição de Cabral foi a
primeira a chegar ao Novo Mundo desde a viagem de Cristóvão Colombo em 1492.
O objetivo da expedição de Cabral era encontrar uma rota marítima para a
Índia, mas quando chegou às costas do Brasil, ele descobriu um novo
continente. A descoberta do Brasil teve um impacto significativo na
história do mundo e marcou o início de uma nova era de exploraçãoStream Execution
import time
start = time.time()
NUM_TOKENS=0
print('-'*4+'Start Generation'+'-'*4)
for token in llm.generate(tokens):
print(llm.detokenize(token), end='', flush=True)
NUM_TOKENS+=1
time_generate = time.time() - start
print('\n')
print('-'*4+'End Generation'+'-'*4)
print(f'Num of generated tokens: {NUM_TOKENS}')
print(f'Time for complete generation: {time_generate}s')
print(f'Tokens per secound: {NUM_TOKENS/time_generate}')
print(f'Time per token: {(time_generate/NUM_TOKENS)*1000}ms')----Start Generation----
I'm trying to learn these in order to pass my chemistry class and I would really appreciate your help!
Thank you!"
Here is a poem to help you remember the first 10 elements on the periodic table:
Hydrogen is number one, light as can be
Helium's next, with a balloon-like spree
Then comes Lithium, shining bright and bold
Beryllium's next, its strength untold
Boron's the next, with a tricky name
Carbon's the one that makes all life the same
Nitrogen's up, with an airy fame
Oxygen's next, for breathing we claim
Fluorine's last, with a twist of fame
I hope this helps you remember the first 10 elements on the periodic table!
----End Generation----
Num of generated tokens: 192
Time for complete generation: 26.46462845802307s
Tokens per secound: 7.2549667683618235
Time per token: 137.8366065522035msLangChain Integration
https://python.langchain.com/docs/ecosystem/integrations/ctransformers
